20191104.1 Pandas Extract vs. Looping with Beautiful Soup
Source file to recreate this can be found here
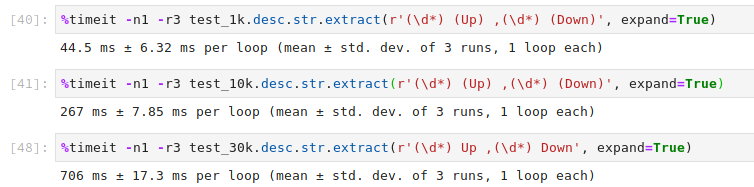
The screenshots show the difference in speeds between two methods for the following sample:
<TABLE>
<TR><TD><B>Close cause</B></TD><TD>Normal Release (0)</TD></TR>
<TR><TD><B>IMSI</B></TD> <TD>272023118178778</TD></TR>
<TR><TD><B>Device IP</B></TD> <TD> 10.2.82.222</TD></TR>
<TR><TD><B>SGSN/SGW</B></TD> <TD> <SPAN TITLE= "80.251.193.210 ">Hi3G Denmark</SPAN></TD></TR>
<TR><TD><B>APN</B></TD> <TD> <SPAN TITLE= "Low Bandwidth APN. ">3iot.com</SPAN></TD></TR>
<TR><TD><B>Bytes</B></TD><TD>1214 Up ,270 Down</TD></TR>
<TR><TD><B>Duration</B></TD> <TD> 00:00:10</TD></TR>
<TR><TD><B>GGSN/PGW</B></TD> <TD> <SPAN TITLE= "185.60.124.148 ">HUE_3IE_SAE02</SPAN></TD></TR>
</TABLE>
The beautiful soup method is as follows:
find_row_by_indexing = bs(x).findAll("td")[11].text
> <td>1214 Up ,270 Down</td>

Against the pandas extract method which is way faster than initialising BeautifulSoup every single time. The extract is better as it extracts the required data faster than the above Beautiful soup code. Additionally, the groups can be customised easily and assigned to columns nicely.
regex_phrase = r'(\d*) (Up) ,(\d*) (Down)'
# For only the digits r'(\d*) Up ,(\d*) Down'
dataframe[colname].str.extract(regex_phrase, expand=True)
> 0 1214 Up 270 Down